

问题描述:[hadoop@usdp01 ~]$ hbase shellSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/usdp-srv/srv/udp/2.0.0.0/hdfs/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]...
回答:Hadoop是目前被广泛使用的大数据平台,Hadoop平台主要有Hadoop Common、HDFS、Hadoop Yarn、Hadoop MapReduce和Hadoop Ozone。Hadoop平台目前被行业使用多年,有健全的生态和大量的应用案例,同时Hadoop对硬件的要求比较低,非常适合初学者自学。目前很多商用大数据平台也是基于Hadoop构建的,所以Hadoop是大数据开发的一个重要内容...
 wizChen
|
1365人阅读
wizChen
|
1365人阅读
回答:Hadoop生态Apache™Hadoop®项目开发了用于可靠,可扩展的分布式计算的开源软件。Apache Hadoop软件库是一个框架,该框架允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。 它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。 库本身不是设计用来依靠硬件来提供高可用性,而是设计为在应用程序层检测和处理故障,因此可以在计算机集群的顶部提供高可用性服务,...
 娣辩孩
|
1642人阅读
娣辩孩
|
1642人阅读
回答:1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。左为Doug Cutting,右为Lucene的LOGOLucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源(...
 ctriptech
|
935人阅读
ctriptech
|
935人阅读

...容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS可以实现流的形式访问(streaming access)文件系统中的数据。 它是基于流数据模式的访问和处理超大文件。(分布式...
...e基于列的而不是基于行的模式。 Kafka角色:Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能...
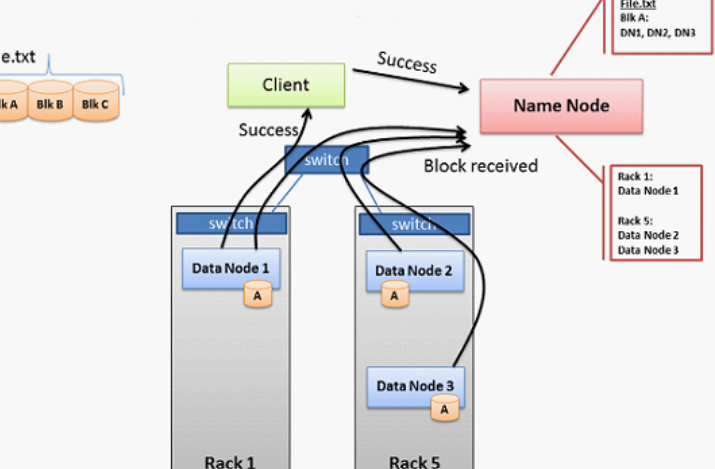
...件上 HDFS适合批量处理,而不是用户交互使用。重点是高吞吐量的数据访问,而不是低延迟的数据访问。 运行在HDFS上的应用程序具有较大的数据集。因此,HDFS被调优以支持大文件。 HDFS设计思想: 分而治之 负载均衡 HDFS...
ChatGPT和Sora等AI大模型应用,将AI大模型和算力需求的热度不断带上新的台阶。哪里可以获得...
一、活动亮点:全球31个节点覆盖 + 线路升级,跨境业务福音!爆款云主机0.5折起:香港、海外多节点...
大模型的训练用4090是不合适的,但推理(inference/serving)用4090不能说合适,...


 dmlllll
dmlllll 邹立鹏
邹立鹏









